A useful feature of statistical systems in social networking backend's is the analysis of when members are mostly, or better said, in average online. Imagine, that we have a database table to store DATETIME-timestamps of when users logged in, which could look like this:
CREATE TABLE login (
login_id INT UNSIGNED AUTO_INCREMENT KEY,
user_id INT UNSIGNED NOT NULL,
login_date DATETIME NOT NULL,
KEY(user_id)
);
For the evaluation, we fetch the relevant data for a particular user in a temporary table to keep further steps easier:
CREATE TEMPORARY TABLE tmp (
tmp_id TINYINT UNSIGNED AUTO_INCREMENT KEY,
tmp_hour TINYINT UNSIGNED NOT NULL,
KEY(tmp_hour)
);
Then we'll fill the table with the necessary data of an example user "123" by using the INSERT SELECT statement of MySQL:
INSERT INTO tmp (tmp_hour)
SELECT HOUR(login_date)
FROM login
WHERE user_id=123;
Based on the data in the temporary table, we create a histogram in order to be able to continue with our analysis. We also cluster the day in common parts to be able to say "Robert is mostly online at night".
SELECT tmp_hour, COUNT(*) tmp_num,
IF(tmp_hour BETWEEN 5 AND 7, 1
IF(tmp_hour BETWEEN 8 AND 11, 2
IF(tmp_hour BETWEEN 12 AND 13, 3
IF(tmp_hour BETWEEN 14 AND 17, 4
IF(tmp_hour BETWEEN 18 AND 22, 5, 0))))) tmp_part
FROM tmp
GROUP BY tmp_hour
The result looks like this:
| tmp_hour | tmp_num | tmp_part |
|---|---|---|
| 0 | 11 | 0 |
| 1 | 7 | 0 |
| 2 | 12 | 0 |
| 3 | 8 | 0 |
| 4 | 6 | 0 |
| 5 | 1 | 1 |
| 6 | 3 | 1 |
| 7 | 1 | 1 |
| 9 | 1 | 2 |
| 10 | 3 | 2 |
| 11 | 8 | 3 |
| 12 | 21 | 3 |
| 13 | 24 | 3 |
| 14 | 18 | 4 |
| 15 | 16 | 4 |
| 16 | 11 | 4 |
| 17 | 8 | 4 |
| 18 | 7 | 5 |
| 19 | 15 | 5 |
| 20 | 13 | 5 |
| 21 | 13 | 5 |
| 22 | 16 | 0 |
| 23 | 2 | 0 |
The third column indicates an index of the partitioned day, that can be used for labeling under the usage of $L_timing:
<?php
$L_timing = array(
'at night',
'in the morning',
'in the forenoon',
'at noon',
'in the afternoon',
'in the evening'
);
Now, we simply need to search the biggest sum of a single group and get, when a user is mostly online, by doing the following:
<?php
$number = array(0, 0, 0, 0, 0);
$max = 0;
$ndx =-1;
while ($row = $res->fetch_assoc()) {
$ref =&$number[$row['tmp_part']];
$ref+= $row['tmp_num'];
if ($ref > $max) {
$ndx = $row['tmp_part'];
$max = $ref;
}
}
echo 'The user is mostly online ', $timing[$ndx];
Okay, that was not really hard so far. Now we focus on finding the daily section, someone is online in average. We use an adapted version of an geometric average for that job. The geometric average is defined as the nth root of the aggregate product over n numbers. Because MySQL doesn't have an aggregate function PROD() to calculate the aggregate product, we must calculate the product differently. We can describe PROD(x) with EXP(SUM(LN(x))) because the the sum of the natural logarithms of every item as the exponent to e is approximately the same as the product of all items. Therefore our query looks like this:
SELECT tmp_hour, POW(EXP(SUM(LN(tmp_num))), 1 / 24) < tmp_num tmp_cover
FROM (
SELECT tmp_hour, COUNT(*) tmp_num
FROM tmp
GROUP BY tmp_hour
)X
The result looks like this:
| tmp_hour | tmp_cover |
|---|---|
| 0 | 1 |
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 0 |
| 5 | 0 |
| 6 | 0 |
| 7 | 0 |
| 9 | 0 |
| 10 | 0 |
| 11 | 1 |
| 12 | 1 |
| 13 | 1 |
| 14 | 1 |
| 15 | 1 |
| 16 | 1 |
| 17 | 1 |
| 18 | 1 |
| 19 | 1 |
| 20 | 1 |
| 21 | 1 |
| 22 | 1 |
| 23 | 0 |
The only thing we have to do with the result is finding the largest set - in general a simple set-cover problem. I thought about the problem, and found a better solution, which can be done the job in O(n/2) in the best case, and O(2n) in the worst case. But at first, I want to show you my first attempt to encounter the problem, by thinking about the result of above as a set of 0 and 1. Then we could iterate over the array and could remove every occurrence of single online states to optimize the set. For example with the following code:
<?php
for ($i = 1; $i < 26; $i++) {
$magic = ($data[($i - 1) % 24][1] << 2) | ($data[$i % 24][1] << 1) | $data[($i + 1) % 24][1];
// 101 || 010
if ($magic === 5 || $magic === 2) {
$data[$i][1] = $magic & 1;
}
}
Then we could cover the set and search for all 1-occurrences:
<?php
for ($i = 0; $i < 24; $i++) {
if (null === $start && 1 === $data[$i][1]) {
$start = $i;
} else if (null !== $start && 1 === $data[$i - 1][1] && 0 === $data[$i][1]) {
$map[$j++] = array($start, $i - 1);
$start = null;
}
}
if (null !== $start) {
$map[$j++] = array($start, $i - 1);
}
Finally, we remap the result, if the online time exceeds 23 o'clock.
<?php
if (0 === $map[0][0] && 23 === $map[$j - 1][1]) {
$map[0][0] = $map[$j - 1][0];
unset($map[$j - 1]);
}
The result for the online behavior is returned via $map and looks like this:
Array
(
[0] => Array
(
[0] => 11
[1] => 3
)
)
But what does this mean? The result can be interpreted as, that we have one set from 11 o'clock in the morning to 3 o'clock in the morning. This results in 16 hours online/working hours in average. I won't tell you, of whom this statistic is :-D
Now let's try to improve the whole thing a bit. I ever said "could this, could that", because the solution above is not my final way to solve this problem. I found a really easy and fast way, by thinking about the online times as an bow in the following form:
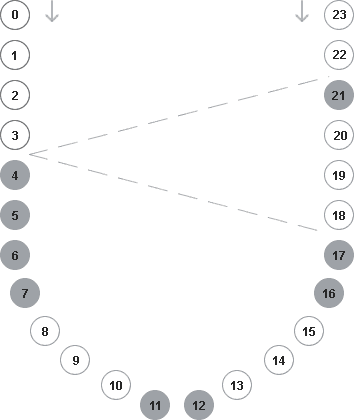
Like on the sketch, we move from top to the bottom, as long as we have no collision with an opposite type. I also defined a threshold to skip single online-hours, if the hours before were more than the given limit. If the limit isn't reached and the other side still have some items of the previous type, we wait with proceeding on the opposite site until the given limit isn't reached. The whole algorithm is implemented as a little procedural function, which looks like this:
<?php
$data = array(0, 0, 0, 1, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0);
function groupCircleTime($data) {
$map = array();
$old = 0;
$run = 0;
$threshold = 2;
$i = 0;
$j = count($data) - 1;
if ($data[$i] == $data[$j]) {
while ($i < $j) {
if ($data[0] == $data[$i] || $run >= $threshold && $data[0] == $data[$i + 1]) {
$i++;
$run++;
}
if ($data[0] == $data[$j] || $run >= $threshold && $data[0] == $data[$j - 1]) {
$j--;
$run++;
}
if ($old == $run) {
break;
}
$old = $run;
}
if ($i < $j) {
$map[] = array($data[0], $j + 1, $i - 1);
$old = $run = 0;
} else {
$map[] = array($data[0], 0, count($data) - 1);
return $map;
}
}
for ($k = $i; $i <= $j;) {
if ($data[$k] == $data[$i] || $run >= $threshold && $data[$k] == $data[$i + 1]) {
$i++;
$run++;
} else {
$map[] = array($data[$k], $k, $i - 1);
$k = $i;
$run = 0;
}
}
if ($k != $i + 1) {
$map[] = array($data[$k], $k, $i - 1);
}
return $map;
}
foreach (groupCircleTime($data) as $d) {
echo implode(' - ', $d), '<br />';
}
The output of the algorithm looks like this:
0 - 19 - 7
1 - 8 - 9
0 - 10 - 16
1 - 17 - 18
... which means, that the user was offline from 19 to 7 and 10 to 16 o'clock, and online from 8 to 9 and 17 to 18 o'clock.