The easiest way to get user statistics from your own site is probably binding third-party tools like, e.g. Google Analytics into your code or parsing the logfiles with AWstats or webalizer. Evaluating your own logged data is the best way to look over the (imaginary) shoulder of users and bots. Moving static content on different servers remain the accesslog also manageable and free from unnecessary data.
If the data is way too much for a single server, this can quickly overcharge the system. Fortunately, we have enough traffic rich pages on the web by now, so there are also many elegant solutions to solve such problems. Using Hadoop and MapReduce is now certainly one of the most efficient ways to retrieve a result from a large dataset in minutes or hours. In this way, parsing and evaluating the data can perfectly be scaled horizontal. The problem of accesslogs are that data is written recurrent over and over again in an easy parseable format to the hard drive. To improve this, I've written my own mod_accesslog which writes the data unformatted and in binary form to the disk. This approach performs much better and saves a lot of disk space and cycles.
The next problem was, however, that a large amount of data lies on every webserver, which can only be fetched up with a certain effort (logrotation, transfer -> bandwidth drop, no real time statistics, ...).
My next thought was that it would be better to log the data right into a MySQL database from which one can easily read the data. To be able to test this idea, I've developed mod_mysql_accesslog for lighttpd.
Surprisingly, the performance was quite better than I've assumed. I now tried to tweak the performance a little, by applying delayed inserts, concurrent_insert option and so on. Anyway, there was still one problem when I tried to read from the table: locks!
Actually, we only want to move the data to another (centralized) server, so why not abusing MySQL replication for that task? We would have no locks anymore and also a buffer is set up between the accesslog and the slave to manage peak times. This idea is also resistant against connection pull downs, because the replication cleanly stops and proceed when the connection is restored.
The good thing about MySQL is that each layer is kept modular and so storage engines can also be chosen freely. The most famous engines are MyISAM and InnoDB, but there are also more exotic ones like Memory, Archive, Federal and Blackhole. Blackhole would be suitable for that task and as it is part of the standard distribution, we have no further changes to do (If it is not enabled by default, rtfm). Blackholes name is really based on a virtual black hole. You can write data to that storage engine but it throws them away, whereby reading data from a Blackhole table ever returns an empty set. Now someone might say that this engine does not make sense, but triggers are executed and also the binlog is touched. This way you can test the performance of the binlog and do some other cool things, but for our case it is more important to get the data into the binlog without producing a local copy in order to replicate the data away.
Thus, our setup looks as follows:
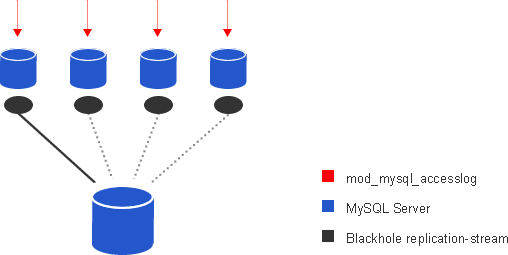
As you can see on the sketch, we have many instances of webservers with a local MySQL server and only one centralized server to analyze the data. Some might say, that this is a SPOF, but this can also be scaled horizontal. You only have to lay a little logic between the servers, in which order a collection server is asked for new data. But I think, this attempt should only be a proof of concept. For real world scenarios, distributed log systems such as rsyslog are probably more appropriate than such hacks.
Well, now lighttpd has a new module which can also be used otherwise. To read how to install mod_mysql_accesslog go to the project page.