The Goal
Using performance measures carried out on the execution time of the programs for Bender, your mission is to determine what's the most likely computational complexity from a family of fixed and known algorithmic complexities.
Example
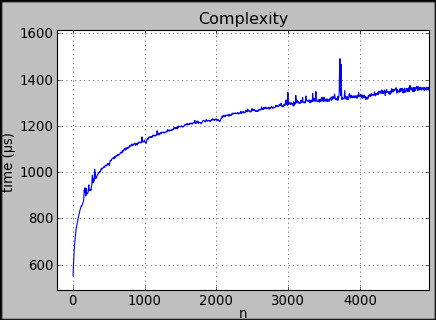
In this example, the program was run with data volumes ranging from 0 to 5000 items and we see that the execution time, measured in microseconds, varies significantly depending on the number of items that the program processed. Here, the curve suggests that the most likely algorithmic complexity is O(log n).
Game Input
Line 1: the number N of performance measures carried out on the same program.
N following lines: one performance measure per line. Each line contains two values: an integer num representing the number of items that the program has processed and an integer t representing the execution time measured to process these items in microseconds. These values are separated by a space. Values of nare unique and sorted in ascending order.
5 < N < 1000
5 < num < 15000
0 < t < 10000000
Solution
In Big O notation a function \(f\) is said to be \(f\in O(g)\) if there exists a \(c\) beginning at a certain point such that for \(x: |f(x)|\leq c\cdot |g(x)|\). For our problem \(c\) becomes a parameter when seeing the computational complexities as a regression model. The easiest and most reliable way to solve this problem is using a least square error approach, where we use the model which minimizes the error with respect to the given data. For a function \(g(x)\) we calculate the error as
\[\sum\limits_{i=1}^n (y_i - c\cdot g(x_i))^2\]
The problem here is the model parameter \(c\), which must be fitted using an optimization algorithm. We throw all assumptions for a proper model fitting to the winds and approximate \(c\) with just one data point:
\[c:= \frac{y_n}{g(x_n)}\]
Since we work with quite large numbers here, we transform everything to log-scale. With this information gathered together, we're ready to implement the algorithm:
var N = +readline();
var X = [];
var Y = [];
for (var i = 0; i < N; i++) {
var inputs = readline().split(' ');
X.push(+inputs[0]);
Y.push(+inputs[1]);
}
function leastError(X, Y, fn) {
var logc = Math.log(Y[Y.length - 1]) - fn(X[X.length - 1]);
var s = 0;
for (var i = 0; i < X.length; i++) {
s+= Math.pow(Math.log(Y[i]) - logc - fn(X[i]), 2);
}
return s;
}
var error = {
'O(1)' : leastError(X, Y, n => 0),
'O(log n)' : leastError(X, Y, n => Math.log(Math.log(n))),
'O(n)' : leastError(X, Y, n => Math.log(n)),
'O(n log n)' : leastError(X, Y, n => Math.log(n * Math.log(n))),
'O(n^2)' : leastError(X, Y, n => 2 * Math.log(n)),
'O(n^2 log n)': leastError(X, Y, n => Math.log(n * n * (Math.log(n)))),
'O(n^3)' : leastError(X, Y, n => 3 * Math.log(n)),
'O(2^n)' : leastError(X, Y, n => n * Math.LN2)
};
var min = Infinity;
var mink = null;
for (var i in error) {
if (min > error[i]) {
min = error[i]
mink = i;
}
}
print(mink); All images are copyright to Codingame