At CodinGame we like to reinvent things. XML, JSON etc. that’s great, but for a better web, we’ve invented our own text data format (called CGX) to represent structured information.
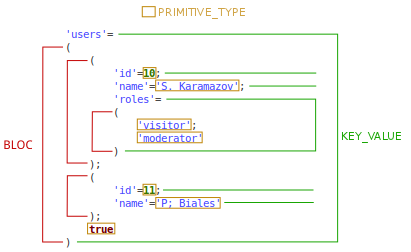
Here is an example of data structured with CGX:


CGX content is composed of ELEMENTs.
ELEMENT
An ELEMENT can be of any of the following types BLOCK, PRIMITIVE_TYPE or KEY_VALUE.
BLOCK
A sequence of ELEMENTs separated by the character ;
A BLOCK starts with the marker ( and ends with the marker ).
PRIMITIVE_TYPE
A number, a Boolean, null, or a string of characters (surrounded by the marker ')
KEY_VALUE
A string of characters separated from a BLOCK or a PRIMITIVE_TYPE by the character =
Your mission: write a program that formats CGX content to make it readable!
Beyond the rules below, the displayed result should not contain any space, tab, or carriage return. No other rule should be added.
- The content of strings of characters must not be modified.
- A BLOCK starts on its own line.
- The markers at the start and end of a BLOCK are in the same column.
- Each ELEMENT contained within a BLOCK is indented 4 spaces from the marker of that BLOCK.
- A VALUE_KEY starts on its own line.e.
- A PRIMITIVE_TYPE starts on its own line unless it is the value of a VALUE_KEY.
INPUT:
Line 1: The number N of CGX lines to be formatted
The N following lines: The CGX content. Each line contains maximum 1000 characters. All the characters are ASCII.
OUTPUT:
The formatted CGX content
CONSTRAINTS :
The CGX content supplied will always be valid.
The strings of characters do not include the character '
0 < N < 10000
Solution
Even if regular expressions are given as a hint, it doesn't make sense to parse a nested structure with regular expressions (since an infinite recursion can't be modeled with a finate state machine, from which follows it's not a type 3 grammer and as such no regular expression can be found). A better approach is tokenizing all valid symbols of CGX and write it to stdout with a clean formatting. This can be separated into two steps, the tokenizing and formatting step, or we write out the data as we get it in. Let's analyze the grammer for this problem. If we get a quote, we need to continue searching until we get the closing quote. Every character in between can be pushed out directly. If we see any whitespace, we simply ignore it. If we get a semicolon, we print it, followed by a new line. If we get an opening bracket, we write a new line character, if we haven't previously printed one. After that, the current indent and the bracket can follow. Almost the same applies for a closing bracket, but in reverse.
As we want to re-format the string only, no context knowledge is needed. Any other token can be printed as is, which results in the following C++ implementation:
#include <iostream>
using namespace std;
int main() {
int INDENT = 0;
bool IN_STRING = false;
bool NEWLINE = true;
int n;
cin >> n;
cin >> noskipws;
for (char c; cin >> c; ) {
if (IN_STRING) {
IN_STRING = (c != '\'');
cout << c;
} else switch (c) {
case '(':
if (!NEWLINE)
cout << endl;
cout << string(INDENT, ' ') << c << endl;
INDENT+= 4;
NEWLINE = true;
break;
case ')':
if (!NEWLINE)
cout << endl;
INDENT-= 4;
NEWLINE = false;
cout << string(INDENT, ' ') << c;
break;
case '\'':
cout << string(NEWLINE * INDENT, ' ') << c;
IN_STRING = true;
NEWLINE = false;
break;
case ';':
cout << c << endl;
NEWLINE = true;
break;
case ' ':
case '\t':
case '\n':
break;
default:
cout << string(NEWLINE * INDENT, ' ') << c;
NEWLINE = false;
}
}
} All images are copyright to Codingame